
TL;DR
This blog post explains how the recent release of DeepSeek may benefit the open source community and why it is considered a game changer for AI industry.
Why all the rumors?
DeepSeek-R1 represents a significant innovation in the AI landscape, outperforming or rivaling top commercial models including reasoning capabilities. Previously, such sophisticated models were exclusive to tech giants like OpenAI and Google, but R1 now joins this category as the only open-weights model of its kind. Its Open Source approach including a MIT license further amplifies its disruptive potential, enabling unrestricted commercial use, even for direct competitors, without costly R&D.
Beyond accessibility, DeepSeek-R1 heats innovation by openly sharing its cost-effective training methodology, challenging the narrative that advanced AI requires exorbitant GPU investments. Operationally, it’s remarkably affordable: output tokens cost 30x less than OpenAI’s, and input tokens are 55x cheaper.
R1’s blend of performance, openness, innovation and affordability could signal that open-source can still play a pivotal role in the AI race.

And yes, it’s a widely discussed topic in the AI community. and still i found it very interesting and entertaining.
DeepSeek Technical Paper in a Nutshell
Key Training Process & Innovations in DeepSeek-R1
1. Two Core Models
DeepSeek-R1-Zero:
- Pure RL Training: Trained directly on the base model (DeepSeek-V3-Base) without supervised fine-tuning (SFT).
- Algorithm: Uses GRPO (Group Relative Policy Optimization), a critic-free RL method that estimates baselines from group scores.
- Reward Design: Relies on rule-based rewards (accuracy + formatting) instead of neural reward models to avoid reward hacking.
- Emergent Behaviors: Self-verification, reflection, and extended reasoning (e.g., “aha moments”) emerged naturally during RL.
- Limitations: Poor readability, language mixing, and formatting inconsistencies.
DeepSeek-R1:
- Cold-Start Data: Starts with thousands of curated CoT examples to fine-tune the base model, improving readability and stability.
- Multi-Stage Training:
- Cold-Start SFT: Initial fine-tuning for readable CoT generation.
- Reasoning-Oriented RL: Applies GRPO with added language consistency rewards.
- Rejection Sampling + SFT: Generates high-quality data (600k reasoning + 200k non-reasoning samples) for retraining.
- Final RL Alignment: Balances reasoning performance with human preferences (helpfulness/harmlessness).
2. Key Innovations
RL-First Approach:
- Proves reasoning capabilities can be incentivized purely through RL without SFT (novel for open research).
- Achieves OpenAI-o1-0912-level performance (e.g., 71% → 86.7% on AIME with majority voting).
Cold-Start Strategy:
- Addresses R1-Zero’s limitations by seeding RL with human-prioritized data (readability, structured outputs).
Distillation Efficiency:
- Smaller models (1.5B–70B) distilled from DeepSeek-R1 outperform RL-trained counterparts (e.g., 72.6% vs. 47% on AIME for Qwen-32B).
- Distilled models surpass GPT-4o/Claude-3.5-Sonnet in math/coding tasks despite smaller size.
Rule-Based Rewards:
- Avoids neural reward models, simplifying training and reducing hacking risks.
3. Critical Challenges & Insights
- Failed Attempts:
- Process Reward Models (PRMs): Struggled with fine-grained step validation and scalability.
- Monte Carlo Tree Search (MCTS): Token-generation complexity made iterative improvement impractical.
- Key Insight: Distillation is more cost-effective than RL for smaller models, but advancing SOTA requires large-scale RL on powerful base models.
Foundational concepts used in DeepSeek-R1
To gain a clearer insight into the core framework of DeepSeek-R1, let’s break down its foundational concepts:
Reinforcement Learning (RL): This approach involves a model learning through a system of rewards and penalties tied to its actions, refining its performance over time via trial and error. In the realm of large language models (LLMs), RL can be implemented through techniques such as policy optimization (e.g., Proximal Policy Optimization or PPO), value-based methods (e.g., Q-learning), or combined approaches like actor-critic architectures. For instance, when presented with a prompt like “2 + 2 =”, the model might receive a reward of +1 for generating the correct answer “4” and a penalty of -1 for any incorrect response. In advanced LLMs, rewards are often derived from human feedback (RLHF) or automated evaluation systems like GRPO.
Supervised Fine-Tuning (SFT): This process involves retraining a base model using a labeled dataset to enhance its performance on a specific task. For example, an LLM could be fine-tuned with a dataset of customer service queries and responses to improve its accuracy in addressing common support questions. This method is particularly effective when a substantial amount of labeled data is available.
Cold Start Data: This refers to a small, minimally labeled dataset used to provide the model with a basic grasp of the task at hand. For instance, a chatbot might be fine-tuned using a simple dataset of frequently asked questions (FAQs) extracted from a website, helping it establish a foundational understanding. This approach is especially useful when labeled data is scarce.
Multi-Stage Training: In this method, the model undergoes training in distinct phases, each targeting a specific improvement, such as accuracy or alignment with user expectations. For example, a model might first be trained on general text data and then further refined using reinforcement learning based on user feedback to enhance its conversational capabilities.
Rejection Sampling: This technique involves generating multiple potential outputs from a model, but only retaining those that meet predefined criteria, such as quality or relevance. For example, after a reinforcement learning process, the model might produce several responses, but only the most useful ones are selected for retraining or further use. This ensures that only high-quality outputs contribute to the model’s ongoing improvement.
How Does DeepSeek Work?
DeepSeek R1 changes the way we think about training AI to reason. Instead of needing huge sets of labeled examples to learn step-by-step logic, R1 shows that a model can develop detailed reasoning skills using only reinforcement learning (RL). Their R1-Zero experiment is the proof-of-concept here—by using a smart reward system, the model learned to work through problems, check its own answers, and even spend extra time on tougher questions. What’s striking is that these skills weren’t explicitly programmed in; they emerged naturally during training.
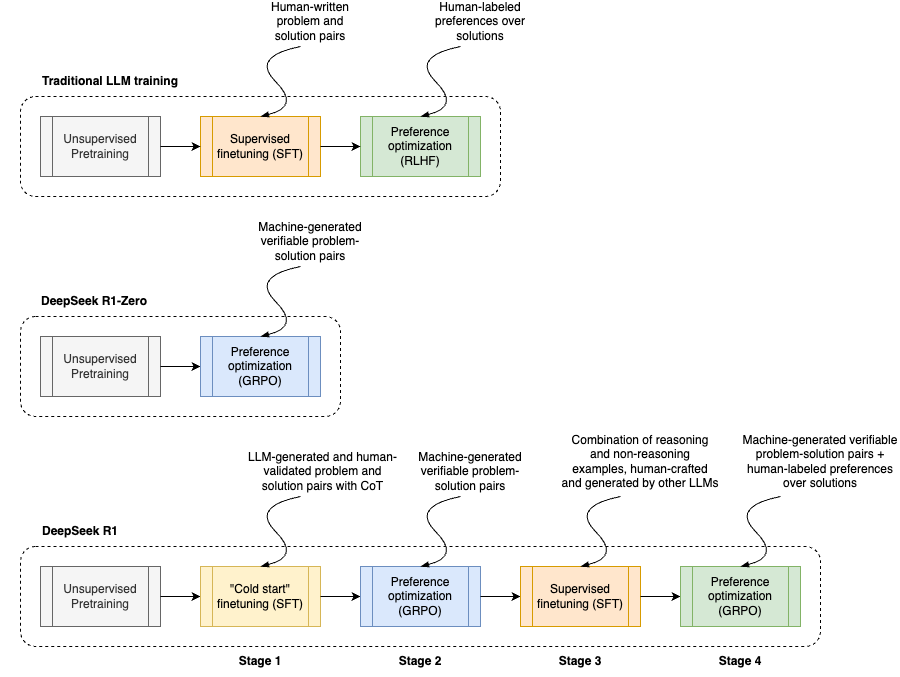
Rethinking Traditional Language Model Training
Most language models go through three main phases:
Pre-training:
The model starts by processing huge amounts of text (web pages, books, papers, code, etc.) to learn language basics like grammar, facts, and simple logic. The goal is to predict the next word in a sequence, and by doing this on trillions of tokens, the model builds a rich understanding of language. However, at this stage, it’s not yet good at applying its knowledge to specific tasks.Supervised Finetuning (SFT):
After pre-training, the model gets fine-tuned on curated datasets with instruction-response pairs. This step teaches the model how to follow instructions, answer questions, summarize text, generate code, and even write creatively. High-quality SFT data is crucial—it’s expensive and tough to create but sets the model up to act more like a human assistant.Preference Optimization:
Sometimes called RLHF (Reinforcement Learning from Human Feedback) or direct preference optimization (DPO), this phase aligns the model’s outputs with what people prefer. Human annotators rate different responses, and the model’s behavior is fine-tuned to favor outputs that score higher. This helps with more subtle aspects like tone, consistency, and safety.
The Role of Chain of Thought
An interesting trick is to have the model generate a “chain of thought” (CoT) before giving its final answer. For example, if you ask, “How much is 1+1?”, the model might internally think through different possibilities before settling on 2. This intermediate step improves accuracy, though most of it remains hidden from users. While some models like OpenAI’s o1 have shown great results with CoT, their process remains secret—leading many to speculate about a “secret sauce” of hand-crafted examples.
DeepSeek R1-Zero and R1: Rethinking the Norm
DeepSeek challenged the usual belief that extensive supervised fine-tuning is necessary. Instead, they showed that a pure reinforcement learning approach, using automatically generated training examples, can yield impressive reasoning skills.
R1-Zero demonstrates that advanced reasoning (or chain of thought) can emerge without the traditional SFT stage. Built on the DeepSeek-V3-Base architecture (with 671 billion parameters), R1-Zero uses 61 Transformer decoder blocks. The first three blocks use dense attention to capture basic patterns, while the remaining blocks use a mixture of experts (MoE). In the MoE setup, instead of processing every token through every expert, a few specialized networks are activated per token. For example, out of 256 experts in each block, only 8 are used for any given token, making the process both faster and cheaper.
Group Relative Policy Optimization (GRPO)
One of DeepSeek’s key innovations is GRPO—a twist on the common RLHF technique known as Proximal Policy Optimization (PPO). In traditional RLHF, you need several components:
- Policy Model (Actor): The model that generates text.
- Reference Model: Usually the frozen SFT model.
- Reward Model: Trained with human ratings.
- Value Model (Critic): Predicts expected rewards for each token.
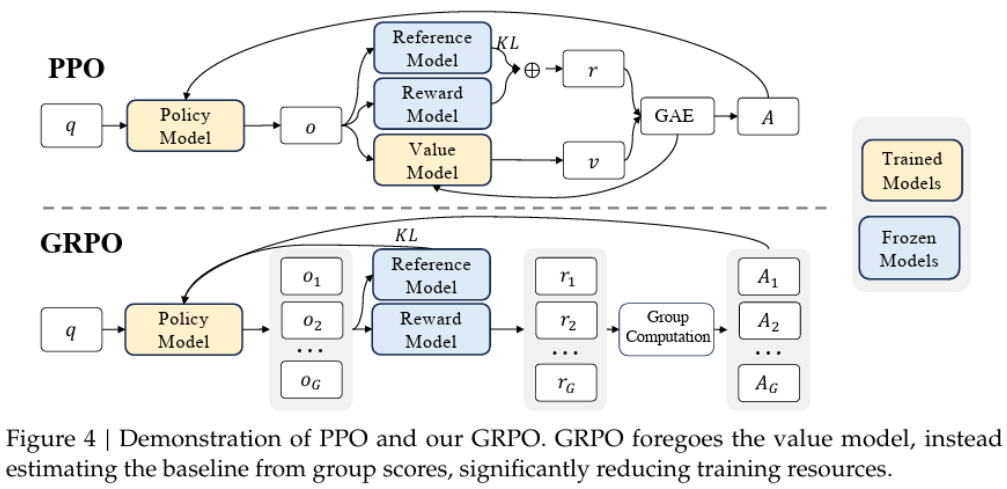
PPO relies on these to update the model based on how much better or worse each token is compared to what was expected. But GRPO cuts out the value model. Instead, it samples multiple outputs for each prompt and uses the group’s average reward as a baseline. For example, if you generate 64 responses for a math problem and one gets 0.9 while the average is 0.7, that answer gets a boost (an advantage of 0.2). This group-based method not only simplifies things but also encourages some pretty neat behavior: the model starts to self-correct, having “Aha moments” where it notices and fixes its own mistakes without explicit instructions.
Reward Structure: Accuracy and Format
DeepSeek’s reward system is another breakthrough. Rather than using a convoluted multi-network approach (which can be tricked by “reward hacking”), they use a simple, rule-based system. The model earns rewards in two main ways:
Accuracy Rewards:
The model’s answer is checked automatically. For math problems, it must match the exact expected answer (often formatted in a specific way). For coding, the generated code is executed and its output is compared to a known correct result.Format Rewards:
The model is also rewarded for writing its reasoning clearly between designated tags (like<think>and</think>). This ensures that its chain of thought is not only correct but also readable and well-structured.
What’s impressive is that this whole system doesn’t rely on human feedback. It scales up quickly because the model can evaluate millions of responses automatically, reducing bias and opening the door to discovering new problem-solving approaches.

Multi-Stage Training Process in DeepSeek R1
Building on the insights from R1-Zero, DeepSeek’s full R1 model uses a four-stage training pipeline to overcome some issues seen in R1-Zero, like messy formatting or mixing languages:
Cold Start Stage:
Here, a small dataset of detailed chain-of-thought examples is gathered. These examples come from several sources: few-shot prompting, cleaned-up outputs from R1-Zero, and even some human post-processing. This dataset helps stabilize the early phase of RL training.Intensive Reinforcement Learning Stage:
The model then undergoes rigorous RL focused on reasoning tasks such as math, coding, and logic puzzles. This stage uses the GRPO framework and adds extra rewards to enforce language consistency—minimizing the tendency to mix languages mid-response.General Finetuning Stage:
At this point, the model isn’t just about reasoning anymore. It’s further tuned with additional data covering general text tasks like writing, translation, and role-playing. Researchers curate about 600,000 reasoning-related examples and another 200,000 non-reasoning samples, combining them for broader capabilities.Preference Optimization Stage:
Finally, a general-purpose RL process is applied to fine-tune the outputs so that they align better with human preferences, refining tone, style, and overall quality.
Implications
The release of DeepSeek-R1 was not just another model but it represents a shift in how advanced LLMs can be built and deployed:
Democratization of Advanced AI:
Against the overwhelming trend of closed-source models, DeepSeek-R1 is open-sourced and still reaches on-par performance with commercial models. This openness invites collaborative improvements and accelerates innovation in AI.
Cost-Effective Scaling:
DeepSeek-R1 dramatically reduces token costs (30× cheaper for outputs and 55× cheaper for inputs than comparable commercial models). This cost efficiency challenges the narrative that state-of-the-art reasoning demands vast GPU clusters and massive labeled datasets, initiating new innovation in AI training paradigms.
Validation of Pure RL for Reasoning:
The success of DeepSeek-R1-Zero proves that advanced reasoning can emerge solely through reinforcement learning. This breakthrough inspires further research into RL-first training paradigms, potentially reshaping how future LLMs are developed.
Influence on Commercial Strategies:
By openly publishing its training methods—including its efficient distillation and group-based optimization techniques—DeepSeek-R1 pressures commercial entities to adopt more transparent and community-friendly approaches. This could lead to a more competitive and innovative AI ecosystem.
Pitfalls
While DeepSeek-R1 sets a new standard, several challenges remain:
Readability and Formatting:
The initial R1-Zero model exhibited issues such as poor readability and language mixing. Although the multi-stage training process addresses these concerns, some residual inconsistencies may persist in complex scenarios.Inference Latency:
DeepSeek-R1’s chain-of-thought generation is computationally intensive. Inference times are slower compared to models optimized solely for speed, which may limit its use in latency-critical applications.Limited Inference Flexibility:
The current API version does not support many adjustable parameters (e.g., temperature, top_p, etc.), making it harder to fine-tune output behavior for production environments.Risk of Overfitting to Rule-Based Rewards:
Relying on fixed, rule-based rewards simplifies training but may also constrain the model’s adaptability. In cases where nuanced human judgment is required, this approach might not capture every subtlety.Scalability of Pure RL:
Although pure RL has proven effective here, it typically requires longer training times and can be sensitive to reward design. The balance between cost-effectiveness and training complexity remains a delicate one.
Conclusion
DeepSeek R1 is a major step forward in AI because it shows that you don’t need a massive, manually curated dataset to get a model to reason well. Instead, by leveraging pure reinforcement learning and a clever reward system, the model learns to think through problems, self-correct, and provide clear, structured explanations on its own.
R1-Zero, combined with the refined multi-stage training process in R1, not only offers competitive performance on tough benchmarks but does so more efficiently and cost-effectively. As these techniques evolve, they’re likely to shape the next generation of Open Source AI models.
Ressources
https://thelmbook.com/articles/#!./DeepSeek-R1.md
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
https://www.vellum.ai/blog/the-training-of-deepseek-r1-and-ways-to-use-it