
LLM Quantization in a Nutshell: A Detailed Exploration
Quantization is a critical technique to reduce the precision of large language models (LLMs), making them lighter and more efficient without a significant loss in performance. This post delves into the nuts and bolts of quantization, explains the underlying math, and examines practical aspects using tools like llama.cpp.
TL;DR
LLM quantization reduces the numerical precision of model parameters to decrease memory usage and improve inference speed. Whether applying post-training quantization or quantization-aware training, the goal is to strike an optimal balance between model efficiency and accuracy. Tools like llama.cpp make deploying quantized LLMs on commodity hardware increasingly accessible.
Introduction to Quantization
The Technical Foundation of LLM Quantization
Quantization, in the machine learning context, means mapping a continuous range of values (usually 32-bit floating points) to a discrete set (such as 8-bit integers). This conversion is similar to reducing the bit depth of an image or audio file: fewer bits mean less data to store and process, which is essential when working with LLMs that can contain billions of parameters.
Illustration: Quantization Process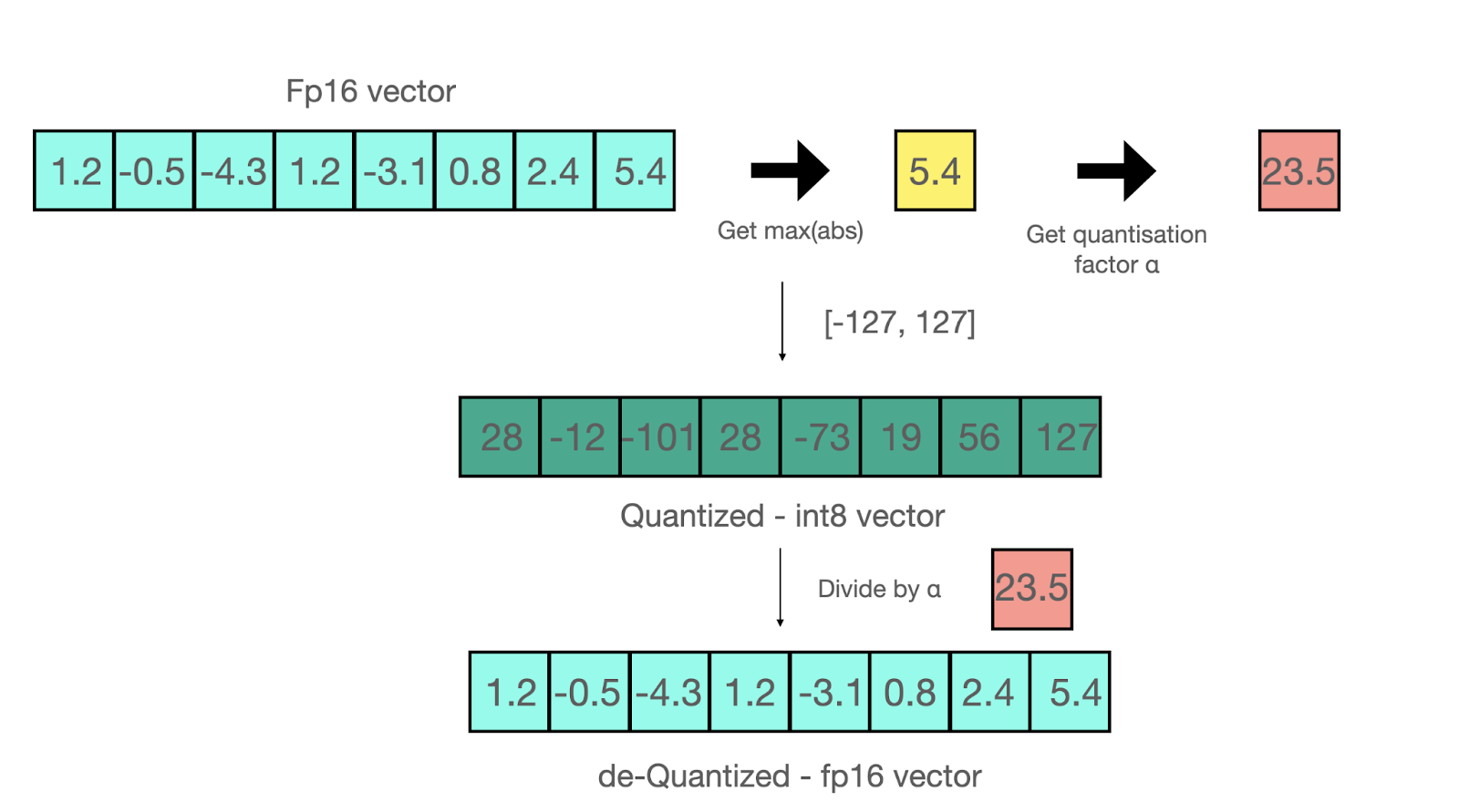
The above diagram represents how continuous floating-point numbers are mapped to a set of discrete values via scaling and rounding.
Understanding Quantization
Quantization relies on two fundamental operations:
- Scaling: Adjusting the range of values so they fit within a target precision.
- Rounding/Truncation: Converting these scaled values into discrete numbers.
Mathematically, for a given weight ( w ), quantization typically follows:
[ q = \text{round}\left(\frac{w}{s}\right) ]
where:
- ( q ) is the quantized integer.
- ( s ) is the scaling factor determined from the range of ( w ).
To recover an approximation of the original weight during inference, the formula is inverted:
[ w \approx s \times q ]
This simple yet powerful operation is applied to all model parameters, significantly reducing the overall memory footprint.
Post-Training Quantization
Post-training quantization (PTQ) is the process of converting a fully trained model’s weights to a lower precision after training is complete. PTQ is attractive for its simplicity and speed. However, since the weights are not optimized for low precision during training, a slight degradation in model performance may occur.
Quantization-Aware Training
Quantization-aware training (QAT) integrates the quantization process into the training phase. By simulating low-precision arithmetic during training, the model learns to adjust its weights to mitigate precision loss. This approach generally yields better performance than PTQ, especially when using very low bit-widths.
Optimization Techniques in Quantization
Once a model is quantized, further optimizations become possible. Choosing the appropriate bit-width is crucial—too few bits and you risk significant accuracy loss; too many and the efficiency gains are marginal. Techniques such as dynamic scaling, careful calibration, and even layer-wise mixed precision are employed to fine-tune performance.
Mathematical Note:
A common enhanced quantization formula incorporates a zero-point ( z ) to better handle distributions centered around zero:
[ q = \text{clip}\left(\text{round}\left(\frac{w}{s}\right) + z,, q_{\text{min}},, q_{\text{max}}\right) ]
This modification helps minimize the quantization error, ensuring the overall model accuracy remains high.
A Technical Examination
Diving Deeper into llama.cpp
llama.cpp is a C++ library designed for running quantized LLaMA models efficiently on CPUs. Its primary goal is to facilitate inference with low-precision models by taking advantage of integer arithmetic. The library’s lightweight design makes it particularly useful for deploying large models on less powerful hardware.
Quantization in llama.cpp
Using llama.cpp involves several key steps:
- Installation & Setup:
Install the library and its dependencies. - Model Conversion:
Convert a pre-trained LLaMA model into a quantized format using provided scripts. - Inference:
Load the quantized model and perform inference efficiently using the optimized C++ routines.
The tool’s script outputs a quantized model file that is specifically formatted for efficient CPU inference.
Storing Quantized Models: GGML & GGUF
Quantized models are typically stored in binary formats such as GGML or its successor, GGUF.
- GGML: Developed by Georgi Gerganov, GGML provides a compact, CPU-friendly storage format.
- GGUF: An evolution of GGML, GGUF is more extensible and optimized for reduced RAM usage.
Where to Find Models
For those looking to experiment with quantized LLMs, the Hugging Face Hub offers a range of pre-quantized models. These models are available in various configurations, allowing users to select a balance between efficiency and accuracy based on their specific use case.
Conclusion
Advantages of Quantization
Quantization reduces the memory footprint and computational requirements of LLMs. This is especially beneficial when deploying models on edge devices or in environments with limited resources. Additional benefits include:
- Reduced Energy Consumption: Lower precision arithmetic requires less power.
- Faster Inference: More efficient computation enables real-time applications.
Challenges and Considerations
While quantization offers compelling benefits, it is not without challenges:
- Accuracy Trade-offs: Lowering precision can lead to minor accuracy degradation, necessitating careful calibration and evaluation.
- Tooling Complexity: Integrating quantization into the training and inference pipelines may require additional tooling and expertise.
Practical Expertise in Quantized LLMs
Mastering quantization involves balancing theory and practice. As techniques evolve, tools like llama.cpp continue to push the boundaries of what is possible, making it easier to deploy efficient LLMs in production environments.
Final Thought:
Quantization is a key enabler for the next generation of LLM deployments, transforming models into agile, resource-friendly systems without sacrificing their impressive capabilities.
For further reading and hands-on experimentation, explore the quantized models on Hugging Face and the llama.cpp repository on GitHub.